
What Scaling Means for Data Engineering in Fabric Environments

Scaling in Fabric environments means you change your resources to handle different amounts of data. You pick the right capacity for what you need. For example, small data works best with F2 and saves money. Medium data fits F32 and gives a good balance. Large data needs F64 or custom setups for better performance.
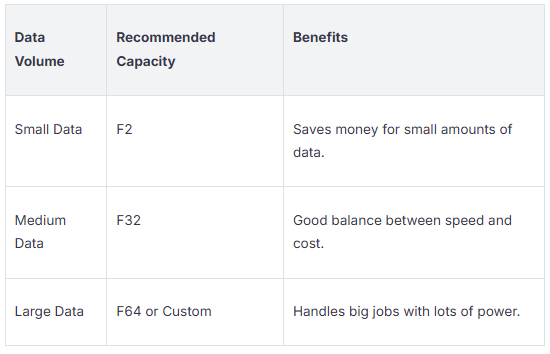
You need strong orchestration, good secu…