

In today’s world, data is very important. The success of your analytics depends on resilient dataflows. Resilient dataflows help businesses deal with challenges and surprises. They make things clearer, help with quick responses, follow rules, and build overall business strength.
Here’s how resilient dataflows affect different parts of your organization:
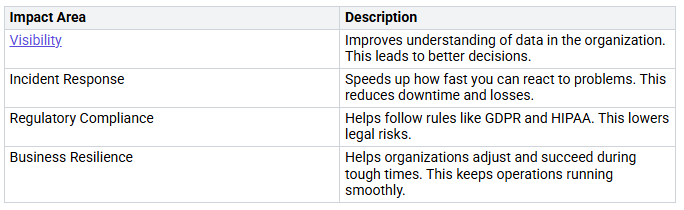
With resilient dataflows, you can create a base that helps your analytics goals.
Key Takeaways
Strong dataflows help you see problems, respond faster, and follow rules. This leads to better choices and lower risks.
Fix schema drift by updating data processing often. This keeps up with changes in data structure and stops failures.
Use a modular design and parameters in dataflows. This makes them more flexible, easier to manage, and stronger against changes.
Keep data safe and correct with automated checks, constant monitoring, and strict access rules. This protects your analytics.
Use a microservices setup and autoscaling. This builds a strong tech framework that adjusts to new needs and boosts performance.
Resilience in Dataflows
Resilience in dataflows means your systems can handle and bounce back from problems. This ability is very important for keeping data available, safe, and correct, especially during surprises like natural disasters or cyber attacks. When you create resilient dataflows, you build a strong base for your analytics work.
Schema Drift
Schema drift is a big problem in data pipelines. It happens when the data structure changes but your data processing logic does not update. Even small changes, like adding a new column or changing a data type, can cause your pipelines to fail. Here are some common reasons for schema drift:
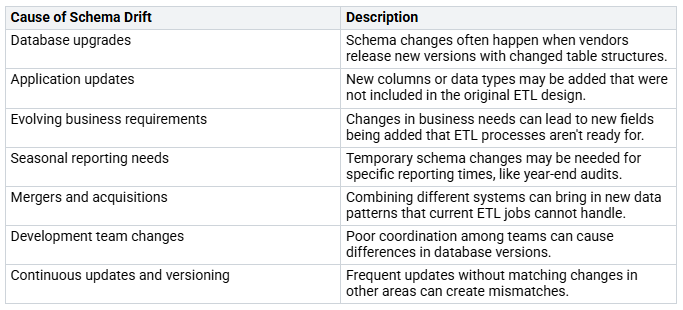
The risks of schema drift can be serious. They include damaged data integrity, security issues, wasted resources, and lost trust among stakeholders. When your data models are inconsistent, mistakes in processing and reporting can lead to wrong business decisions.
Design Fragility
Design fragility means your dataflows are weak. When you hardcode values or assume things about data structures, you make a system that is hard to keep up. Here are some ways to reduce design fragility:
Combine data with centralized repositories to lower complexity.
Use strong data governance rules to ensure consistency.
Create a scalable data plan to support future growth.
Set up real-time data monitoring and quality checks to keep integrity.
Use cloud-based solutions for better flexibility.
Improve teamwork across departments to remove data silos.
Use automation for data integration to keep information current.
By fixing these problems, you can create resilient dataflows that adjust to changes and grow well. This method not only protects your analytics but also improves your overall setup for distributed data processing.
Strategies for Scalable Dataflows
Making scalable data pipelines is very important for modern analytics. You must design your dataflows to handle growth and changes well. Two main strategies to do this are modular design and parameterization.
Modular Design
Modular design splits your dataflows into smaller, easier parts. This method has many benefits:
Reusability: You can use the same modules in different projects. This saves time and effort.
Simplified Management: Smaller modules are easier to take care of and update. You can work on one part without changing the whole system.
Enhanced Resilience: If one module fails, it won’t stop the whole pipeline. You can find problems and fix them quickly.
Modular design also helps with scalability. As your data needs grow, you can add new modules without changing the old ones. This flexibility lets your system grow with your business. For example, a modular monolith architecture keeps one codebase while making management and deployment easier. You can add new modules when needed, so your system can change with demands.
Parameterization
Parameterization makes your dataflows more flexible and easier to maintain. By using parameters, you can create adaptable pipelines that fit different situations. Here are some key benefits:
Increased Flexibility: Parameters let you change your dataflows without rewriting code. This adaptability is important for keeping data pipelines ready for the future.
Reduced Failures: Clear parameter contracts and default values help lower pipeline failures. You can set up your dataflows to handle different inputs smoothly.
Improved Collaboration: Clear parameter usage helps teamwork among data teams. Everyone knows how to use and change the parameters, leading to better workflows.
Adding parameters to your data integration strategies makes your pipelines stronger against changes. You can easily adjust to new needs or environments, making sure your analytics stay reliable.

By focusing on modular design and parameterization, you can create scalable data pipelines that meet your organization’s growing needs. These strategies not only improve performance but also keep your dataflows strong when things change.
Ensuring Data Integrity and Security
Data integrity and security are very important for reliable analytics. You need to use best practices to protect your data and follow rules. Here are some good strategies:
Automated data validation: This keeps datasets consistent and accurate.
Continuous integration (CI) pipelines: These find errors early in your data models.
Automated monitoring and alerting: Use these systems to watch for data problems in real-time.
Data observability tools: These tools check the health of your data systems automatically.
Schema change detection: Use this to quickly find and fix unwanted changes.
Regular training: Teach your staff about data handling to create a culture of responsibility.
You should also focus on security to protect your data pipelines. Common threats include unauthorized access, breaches from misconfigured APIs, and loss of data integrity. To reduce these risks, think about these:
Access control: Limit permissions to only those who need them.
Data encryption: Encrypt sensitive data to keep it safe from unauthorized access.
Regular backups: Keep recovery plans ready to restore data if lost.
Audit trails: Keep logs of data changes to track any issues.
Delta Lake Benefits
Delta Lake improves data integrity and reliability in your analytics workflows. It has several key features:
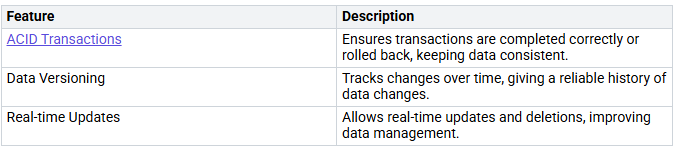
Delta Lake’s design makes sure all operations are atomic, consistent, isolated, and durable. This stops data conflicts and keeps integrity during constant read and write actions. The enforced schema stops bad data from entering the lake, while the time travel feature lets you access old data versions for audits and rollbacks.
Performance Optimization
To keep secure and reliable dataflows, you should improve performance. Here are some good techniques:
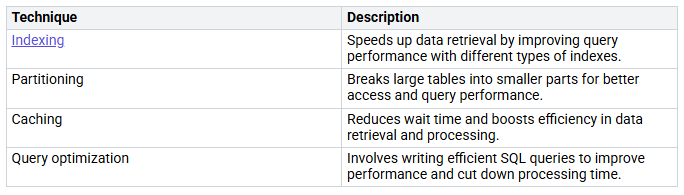
By using these strategies, you can make sure your dataflows stay strong, secure, and efficient, which helps your analytics goals.
Resilient Technology Architecture
A strong technology architecture is very important for building resilient dataflows. It helps your analytics systems handle problems and adjust to new needs. Two main parts of this architecture are the microservices approach and autoscaling.
Microservices Approach
The microservices approach divides data processing into small, separate services. Each service talks to others through APIs. This makes the system stronger by keeping failures from spreading. Here are some benefits of using a microservices architecture:
Service Independence: You can create and launch each service on its own. This allows for quicker updates and improvements.
Decentralized Data Management: You have the freedom to choose data models and technologies that work best for you.
Fault Isolation: If one microservice has a problem, it won’t affect the whole application. This separation boosts overall resilience.
To use this approach well, think about these challenges and solutions:
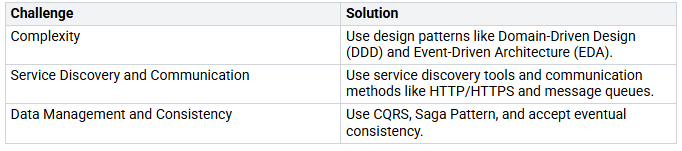
Autoscaling
Autoscaling makes your analytics data pipelines more reliable. It changes computing resources in real-time based on demand. This improves performance during busy times and saves money when activity is low. Here are some key parts of autoscaling:
Dynamic Resource Adjustment: Resources change based on real-time needs, improving performance during busy times.
Cost Efficiency: You save money during slow times by reducing resources.
Understanding Metrics: Knowing metrics like CPU and memory use is important for good scaling strategies.
To make sure autoscaling works well, follow these steps:
Adjust infrastructure behavior to fit the actual needs of each model.
Don’t just rely on reactive triggers or defaults.
Use planned scaling strategies to avoid overprovisioning.
By using a strong technology architecture with a microservices approach and autoscaling, you can create strong and flexible dataflows. This architecture not only meets your current analytics needs but also gets you ready for future growth and challenges.
Building strong dataflows is very important for modern analytics. You can make your data processing better by using new technologies like AI and cloud computing. These tools help with access and growth.
To make sure you succeed, focus on these key strategies:
Prioritize data governance: Keep data quality and follow rules.
Invest in training: Teach your team the skills for good data management.
Foster collaboration: Encourage teamwork between data and risk management teams.
By using these practices, you can create a strong data environment that helps your analytics goals and boosts business success. Remember, strong dataflows not only protect your data but also help your organization do well in a fast-changing world. 🌟
FAQ
What is schema drift, and why is it a concern?
Schema drift happens when your data structure changes but your processing logic does not. This can cause your pipelines to fail and create data problems. It is very important to check and update your dataflows often.
How can I make my dataflows more resilient?
You can make your dataflows stronger by using modular design and parameterization. These methods help you update easily, handle errors better, and adjust to changes in data needs or structures.
What role does Delta Lake play in data integrity?
Delta Lake keeps data safe through ACID transactions and schema rules. It stops data from getting damaged and allows you to track changes. This way, you can go back to earlier versions if needed.
Why is a microservices architecture beneficial for dataflows?
A microservices architecture helps by keeping services separate. If one service has a problem, it won’t affect the whole system. This separation lets you update services independently and improves fault tolerance.
How does autoscaling improve dataflow performance?
Autoscaling changes computing resources based on real-time needs. This helps keep performance high during busy times and saves money when activity is low. It keeps your dataflows efficient and quick to respond.
