

You’ll discover a significant distinction between a Lakehouse and a Warehouse. While both leverage OneLake and the Delta format within Microsoft Fabric, their core functionalities, use cases, and required skill sets diverge. Microsoft Fabric, as a unified platform, accommodates both approaches. This blog post will delve into each, highlighting their differences so you can choose the best option or even combine them for your data architecture within Microsoft Fabric.
Key Takeaways
A Fabric Lakehouse handles all types of data, like structured and unstructured. It is good for AI and machine learning projects.
A Fabric Data Warehouse works best with structured data. It is great for business reports and dashboards using SQL.
Your team’s skills matter. If they know Spark, a Lakehouse is good. If they know SQL, a Warehouse is a better fit.
You can use both a Lakehouse and a Warehouse together in Fabric. This creates a strong system that handles all your data needs.
The Fabric Data Lakehouse
Lakehouse Core Characteristics
A lakehouse in Fabric is great for your data. It is very flexible. It handles all kinds of data. This includes structured, semi-structured, and unstructured data. It puts everything in one place. This makes things less complex. It also saves money. You get one platform. It brings together different types of data. This makes data easier to get. Your data will be consistent. It will be managed and current. This is good for advanced analytics and AI. The lakehouse architecture also gives you real-time insights. You can see user actions right away. You can also track inventory instantly. It stores and processes lots of different data. It does this without the high costs. Traditional data warehouses are more expensive.
Lakehouse Development Interfaces
You have many ways to build things. This is true in a Fabric Lakehouse. Data Flows (Gen 2) in Fabric are important. You make these with visual tools. They use Power Query. This makes loading data easy. Every lakehouse gets a SQL Analytics Endpoint. This endpoint lets you see and query tables. You use SQL SELECT statements. Data analysts know Power BI. They can use the Visual Query Editor. This lets them use Power Query skills. They can make visual queries. Find this under ‘New SQL query’.
Lakehouse Use Cases
The Fabric Lakehouse is good for many things. It is especially good for flexibility and speed. It works well for companies. They handle many data types. This includes structured, semi-structured, and unstructured data. They also need real-time analytics. This makes it perfect for training machine learning. It is also good for exploring data. It can run complex algorithms. Data scientists and engineers can work together. They do not need to move data. It combines data lake storage. It also has data warehouse features. This includes metadata and ETL. It balances different data types. It also provides structure. It goes beyond normal business intelligence. It supports advanced analytics. It uses real-time data.
The Fabric Data Warehouse
Warehouse Core Characteristics
A data warehouse in Fabric uses structured data. It is great for SQL users. This warehouse gathers data. It comes from many places. It makes one true data source. This ends data silos. You get better analytics. These help find trends. They show patterns. This helps business choices. New data warehouses make data better. They clean data. They change data. This makes data correct. It makes data trustworthy. You get faster searches. You get full reports. This shows your business. It shows your customers. This helps predict things. It helps make choices.
Warehouse Development Interfaces
You can build things. Use a Fabric Data Warehouse. SQL Server Management Studio works. Azure Data Studio is good. Visual Studio Code also works. The Fabric website is an option. These tools use your SQL skills. You can make data models. You can manage them.
Warehouse Use Cases
A Fabric Data Warehouse is very good. It has specific uses. It gives one fast place. Business intelligence teams use it. It has standard tables. Definitions are the same. Column storage loads dashboards faster. Materialized views help with math. You get strong tool links. Access is based on roles. This means faster reports. Hard searches run fast. Dashboards refresh quickly. They do not slow other apps. Central data models reduce metric differences. This is true across teams. You can make queries run better. You can use storage types. You can use indexing. This makes searches faster. Partitioning and clustering cut scan costs. For example, date partitioning helps queries. It can make them 80% faster. Sparse indexing speeds up finding things. An index on customer ID helps. It can cut lookup times by 70%. Materialized views do math early. This makes queries much faster. A view for monthly money helps. It can cut query time from 30 seconds to tiny bits. This helps you get insights fast. This warehouse is made for speed.
Lakehouse and a Warehouse: Comparison
You know the basics now. You understand both a Lakehouse and a Warehouse in Fabric. Let’s compare them. This shows their good and bad points. It helps for different jobs.
Data Type Support
They handle data types differently. A Fabric Lakehouse is very flexible. It works with many data types. This includes structured data. It also handles semi-structured data. It can manage unstructured data. You can store any file type. This is in its unmanaged area. For tables, it uses CSV, Parquet, and Delta formats.
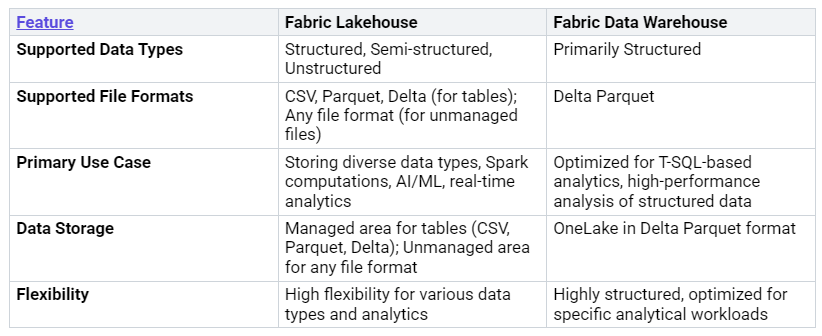
A Fabric Data Warehouse is different. It mainly uses structured data. It stores data in Delta Parquet format. This is inside OneLake. This is great for organized data. It works best with T-SQL analytics. This means neat rows and columns.
Development Experience
How you work with them differs. This depends on your job.
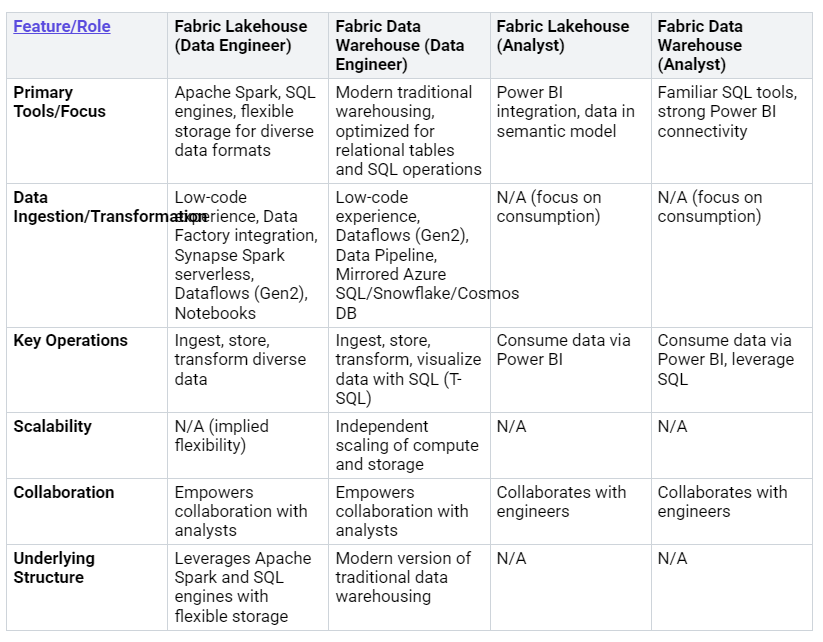
As a data engineer, you use a Lakehouse. You use tools like Apache Spark. You also use SQL engines. You put in, store, and change data. You can use low-code options. Data Factory, Synapse Spark, Dataflows (Gen2), and Notebooks are options. For a data engineer in a Warehouse, you work with modern warehousing. You make relational tables better. You also use SQL operations. You use low-code tools. Dataflows (Gen2) and Data Pipelines are used.
If you are an analyst, you use data. With a Lakehouse, you use Power BI. You work with data models. For a Warehouse, you use SQL tools. You also use Power BI. Both systems help people work together.
Transactional Capabilities
Both systems keep data safe. A Lakehouse uses Delta Lake. This adds ACID transactions. ACID means Atomicity, Consistency, Isolation, and Durability. These make sure data is right. Delta Lake uses a log system. This is for each table. It helps with versions and checks. It makes data easier to use. It also makes it faster.
But there is a key difference. Delta Lake’s ACID rules are for one table. This is not like old databases. They can change many tables at once. The Fabric Lakehouse SQL endpoint is read-only. This is for writing. SQL operations often use many tables. Delta Lake cannot promise ACID for many tables. This would not meet your needs. Apache Spark is the main tool. It writes to Lakehouse Delta tables. Spark works well with Delta Lake. It uses one-table transactions.
Old data lakes often lack these rules. This can cause problems. Data can get bad from failed jobs. You might have issues with many users. Data might not match up. Lakehouses fix these problems. They add database features. This is on top of storage. Open table formats like Delta Lake are key. They do things one at a time. They show consistent data. They control many users. They keep data safe.
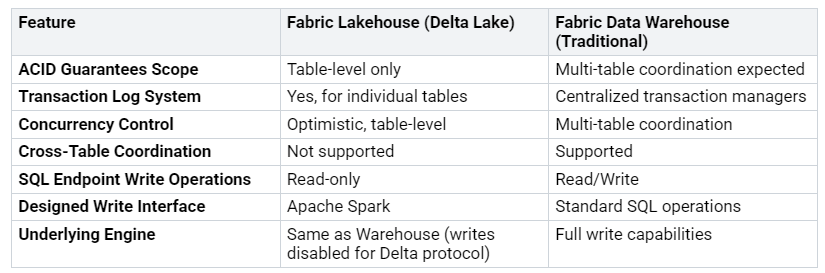
A Fabric Data Warehouse is like old databases. It needs many tables to work together. This is for ACID rules. It uses central managers. It can read and write fully. This is through standard SQL.
Performance Optimization
You can make both systems faster. But the ways are different.
For a Fabric Data Warehouse, you filter early. This helps with columns. They have few unique values. You can use query plans. Hints help fine-tune. The Warehouse warns you. This is for slow operations. It lets you force distributed plans. It also does automatic upkeep. This includes data packing. It also updates stats. It uses T-SQL. This means less manual work. It helps with time-series data. This is for dashboards. They only scan needed parts. Fabric Capacity scales automatically. This is for busy times.
For a Fabric Lakehouse, you do more upkeep yourself. You use notebooks or Spark jobs. You run commands like VACUUM and OPTIMIZE. These pack data. They clean old files. They organize data. This makes queries faster. It saves storage. You can automate some tasks. But it is not as automatic. The Lakehouse uses V-order. This makes data better. It helps with compression. It speeds up queries. This is true for Direct Lake mode. Deletion vectors help manage data. Warming the Direct Lake cache helps. Shortcuts let Power BI see data. It sees Lakehouse and Warehouse data. It is like they are in one place. This reduces extra work. Materialized shortcuts help. Pre-aggregation can reduce joins. This helps you get insights faster.
Security Models
Both systems have strong security. You can control who sees data.
Row-Level Security (RLS): Both have RLS. This is for the Fabric Warehouse. It is also for the Lakehouse SQL endpoint. This lets you control rows. For example, a US analyst sees only US sales.
Column-Level Security (CLS): Both also have CLS. This is for the Fabric Warehouse. It is also for the Lakehouse SQL endpoint. This gives more control. You can allow only certain columns.
Object-Level Security (OLS): This is in the Fabric Warehouse. It is also in the Lakehouse SQL endpoint. OLS controls access. This is for database objects. These include tables, views, or procedures. You use
GRANT,DENY, andREVOKE.

A new Fabric feature is Folder-level Access Control. This uses OneLake Data Access Roles. It controls access to folders. It also controls files in OneLake. These roles are for direct OneLake users. They only work for Lakehouse items now. Remember, workspace roles are stronger. They can override read permissions.
Choosing Lakehouse or Warehouse
You need to pick the right tool. This is for your data work. This choice depends on many things. Think about your data. Think about your team. Think about what you want to achieve.
Lakehouse Selection Factors
You might choose a Lakehouse. This is if your data is very diverse. A Lakehouse handles many types of data. This includes structured data. It also handles semi-structured data. It handles unstructured data. You can store any file type. This is in its unmanaged area. This gives you great flexibility.
Consider a Lakehouse. This is if you work with advanced analytics. It is perfect for machine learning. It is also good for artificial intelligence workloads. You can train recommendation models. Do this directly on unified data. You use Notebooks for this. You can also predict equipment failures. Use machine learning models. A Fabric Lakehouse helps you prepare data. This is for these models. It also supports real-time analytics. It links raw data storage. This is to useful business insights. This makes it a key part. It is for modern analytics. You can use it for machine learning. You can use it for real-time analytics. You can use it for streaming data.
💡 Tip: Choose a Lakehouse. This is when you need to combine many data types. This is for advanced AI and machine learning projects.
Warehouse Selection Factors
You should choose a Warehouse. This is if your data is mostly structured. A Warehouse is best for tables. These have clear schemas. This makes it perfect for fact tables. It is also good for dimension tables. These are common in a star schema. It makes sure your data types are always the same. This is very important. It is for accurate analytics.
A Warehouse is great. It is for enterprise reporting. It is also for business intelligence dashboards. It is the best choice. It is for powering Power BI dashboards. It also works well for Excel reports. It is good for operational analytics. It uses structured data. This data is well-modeled. It supports DirectQuery. This is for real-time data. It is also very fast. It is for adding up numbers. It is for joining data. You get a SQL-first experience. This means you use SQL for everything. This is familiar. This is if you know SQL Server. It supports T-SQL queries. It supports views. It supports stored procedures. This makes it ideal. It is for BI and reporting. It handles large amounts of structured data very well. It can manage billions of rows efficiently. This is partly because of columnstore indexing. A Warehouse can also combine data. This is from many sources. This creates one true source. This is for your analytics.
Team Skills and Infrastructure
Your team’s skills play a big role. If your team knows SQL well, a Warehouse might be easier. They can use their existing knowledge. They can quickly build data models. They can also manage them. The Warehouse uses familiar SQL tools.
If your team has strong skills. This is in Spark, Python, or Scala. A Lakehouse might be a better fit. These tools are common. They are in data science. A Lakehouse lets them use these skills directly. They can work with diverse data formats. They can also build complex data pipelines. Think about your current tools. Think about your systems. Do they work better with a flexible data lake? Or a structured data warehouse?
Analytical Needs
Think about what kind of analysis you need. If you need historical data analysis, a Warehouse is a good choice. It handles high throughput. It is not designed for real-time data. It works with relational data. It works with structured data.
For real-time analytics, a KQL Database is often the best choice. It is built for this specific need. It offers very low latency. It handles streaming data. It handles operational analytics. It works well with IoT. It works with logs. It works with event-based data. A Lakehouse might work for real-time needs. But it depends on the details. If transactions are millions per second. This is with only a few hundred rows each. A Lakehouse might handle it. But if millions of transactions. These have hundreds of thousands of rows each. A Lakehouse cannot handle that load. A Data Warehouse is not suitable. It is not for real-time analytics solutions. It is not designed for ultra-low latency. It focuses on historical data. The choice depends on your exact speed needs.

Integrating Lakehouse and Warehouse
You can mix a Lakehouse and a Warehouse. This is in Fabric. This makes a strong hybrid system. This way helps you use the best parts. It fixes old data warehouse problems. You handle all data types. This is on one platform.
Hybrid Architecture Benefits
A mixed setup has many good points. You get one data layer. This joins structured data. It also joins semi-structured data. It joins unstructured data. You can do both batch and real-time work. This gives you quick answers. It also helps with long-term trends. The system can grow big. It handles much data. It does not slow down. You get many uses. You store different data types. This is in one place. This setup helps advanced analytics. It helps machine learning. It helps AI tools. It also saves money. Storing huge amounts of data costs less. You get better data rules. This is by mixing data sources. You use a standard plan. This makes security better. It makes access better.
Medallion Architecture Example
You can use the Medallion Architecture. This is with Fabric. This is a common way to mix a Lakehouse and a Warehouse.
Bronze Layer: You use a Lakehouse here. It keeps raw data. This data is not changed. It is a copy from your sources. Delta tables work well.
Silver Layer: You can use a Warehouse here. It holds clean data. This data is formatted. You take out extra data. You set it up like a star.
Gold Layer: You often pick a Fabric Data Warehouse. This is for this layer. It uses T-SQL features. This layer adds business rules. It gets data ready for reports.
Data Flow Patterns
You need ways to move data. This is between these layers. Data Pipelines help you plan tasks. They get, load, and change data. You can make reusable code. Dataflows give a visual tool. They use Power Query. This is for ETL logic.
For loading data:
Bronze Layer: You load data here. You often clear it. Then you load it again.
Silver Layer: This layer handles updates. It also handles new data. You use stored procedures.
Gold Layer: You make stored procedures. This is for this layer. They update and add data. This is for your tables.
Combined Architecture Best Practices
You must manage data well. This is in a mixed setup. Use strong data rules. Control who sees data. Catalog your data. This makes sure data is good. Check and improve storage often. Save or delete old data. This lowers costs. Use strong rule systems. They include exact access rules. Use Microsoft Purview. This is for sorting and rules. Use role-based access control (RBAC). This limits access to private data. Make data storage better. Split data by key columns. Combine small files. Use V-Order. This helps organize data. This makes searches faster.
Both Lakehouse and Warehouse are strong parts. They are in Microsoft Fabric. Each is good for different things. Pick the best one. Match it to your business needs. Think about your data. Think about your team’s skills. Know their different jobs. Learn when to use each. Or learn how to join them. This gives you a full data system. It can grow big. It is flexible. Microsoft Fabric helps both ways. This lets your group build good data tools.
FAQ
What is the main difference between a Lakehouse and a Warehouse in Fabric?
A Lakehouse works with all data. It is for AI and machine learning. You use Spark. A Warehouse uses structured data. It is for business intelligence. You use SQL. They meet different needs.
When should you choose a Lakehouse in Fabric?
Choose a Lakehouse for many data types. It is good for AI and machine learning. Use it for real-time data. It is flexible with unstructured data.
When should you choose a Warehouse in Fabric?
Pick a Warehouse for structured data. It runs business dashboards and reports. Use it for quick SQL searches. It is best for neat data.
Can you use both a Lakehouse and a Warehouse together in Fabric?
Yes, you can mix them. This makes a strong system. You get the best of both. It handles all data types. It meets all your needs. It is a full data answer.
